This document covers building a TCW database for a single species. Terminology:
- Dataset is one of the following:
(1) A file of sequences with optional count data from conditions, where the sequences can be nucleotide or amino acid.
(2) A set of sequences to assemble, with optional quality data.
- Conditions may be tissues, treatments, etc that are to be compared, with optional replicates.
- AnnoDBs are fasta files of sequences (nucleotide or amino acid) to compare the dataset sequences
against for annotation. TCW provides special support for UniProt, but can use any file of sequences (e.g. Genbank nr),
see runAS for obtaining and formatting the files.
- NT-sTCWdb is a database built with nucleotide sequences. AA-sTCWdb is a database built with amino acid
sequences.
Contents
Before starting the demo, follow steps for Installation.
Make sure your HOSTS.cfg is correct.
The following three demos are supplied with the package.
| Demo | Description | Documentation
|
|---|
| demoTra | Transcripts with counts, locations, remarks | This section
|
| demoAsm | Assemble transcripts and ESTs | Assembly Guide
|
| demoPro | Protein sequences with counts | Same steps as for demoTra
|
|
At the command line, type
./runSingleTCW
The window shown on the right will be launched.
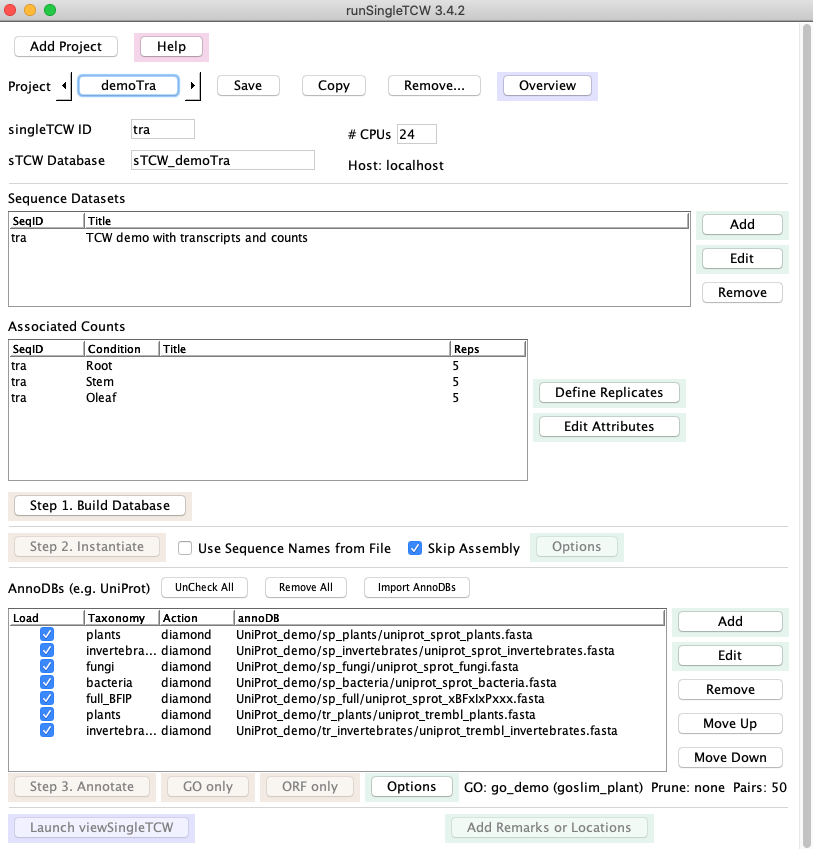
Select demoTra from the Project drop-down list.
1. Click the Step 1. Build Database button.
This loads the datasets in this section; there is one
dataset of transcripts with count data for three
conditions ("Stem","Root","OLeaf"), with five replicates each.
Note:
- A command button will turn gray while it is
executing, and there will be output to the terminal with any errors, warning and the state of execution.
- A command button will not be active when it is not valid to run, e.g.
the Instantiate command is grayed out since the datasets have not been loaded.
2. Click the Step 2. Instantiate button.
- The Skip Assembly was checked so the transcripts will simply be loaded, without
assembly.
- The Use Sequence Names From File is not checked, meaning that the TCW will assign new,
sequentially-numbered names prefixed by the singleTCW ID.
From this point on, you may Launch viewSingleTCW or select the Overview button to check status.
|
|
3. Click the Step 3. Annotate button.
This searches against several UniProt partial databases which have been provided as part of the package.
There may be one or more yes/no prompts for you to answer at the
terminal; keep an eye on the terminal until it says "Start annotating sequences",
at which point, it will run without any further prompts. For example,
if the GO database has not been built yet (see Step 5), the following will be written to the terminal:
+++Warning: GO_tree go_demo is missing; ignoring GO step
--Please confirm above parameters. Continue with annotation? (y/n)?
Answer 'y' to continue.
→Log file: The output to the terminal and to the file projects/demoTra/logs/anno.log will look something like
this log (this includes the GO annotation).
4. Click the Add Remarks or Location button (bottom of window), a window will popup (not shown).
- Select the "..." on the same line as the label Location file:, select the file "traLocations.txt",
then select the button Add on the same line.
- Select the "..." on the same line as the label Remark file:, select the file "traRemarks.txt",
then select the button Add on the same line.
5. To build the GO database, see
Demo annotation setup. Then execute GO Only.
Time for adding the GOs:
This take longer than the other TCW steps, where it can takes around 2 to 5 minutes for this demo.
If it takes a lot longer than 4 minutes for this step,
check your max_allows_packet (see Trouble shooting).
6. To compute differential expression (DE), install R and the respective packages. From the command line, execute
./runDE tra
The DE Guide describes how to install the necessary
packages, and how to add DE p-values to the TCW database. If Step 5 has been run, then you can also add
the p-values for the GO.
→Overview: See overview for the final demoTra overview from the above 6 steps.
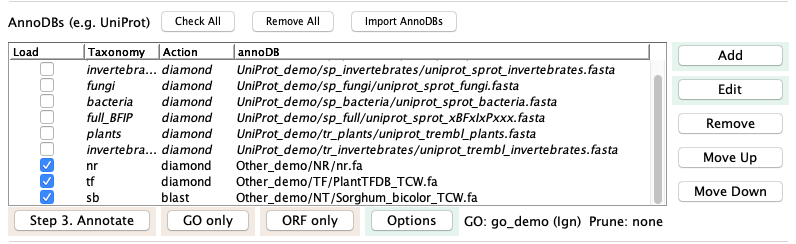
7. (Optional) Add non-UniProt annoDBs
- Back on the main window, select Check All then UnCheck All, which unchecks all current annoDB entries.
- Select Import AnnoDBs, then select file AnnoDBs_other.cfg. The AnnoDB table will look like the figure below.
- GOs: If you add more UniProt databases, you will want to redo GO.
But since none of these annoDBs have GOs, the GO computation does not need to be redone;
on the Options panel, select Ignore on Annotate (the "(Ign)" indicates
this has been set).
- Pairs: if you had previously computed pairs, go to Options and unselect this option.
- Select Annotate:
|
|
On Annotate, you may either select "Use Defaults" on the
popup, where the default is to add to the existing annotation, or select "Answer", where you will
see at the terminal (enter "a"):
?--Annotation exists in database. Enter [a/d/e]
Add to existing annotation [a], Delete annotation [d], Exit [e]: a
Read Creating AnnoDBs from other databases
to see how these were formatted.
Before starting, follow the steps of Installation.
Make sure your HOSTS.cfg is correct.
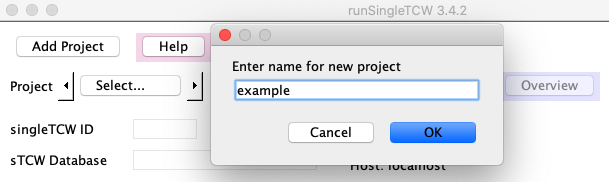
To create a new project, press the Add Project button at the top of the runSingleTCW interface.
You will be prompted for a project name; enter a name using letters, numbers, or underscores (no spaces).
When you select "OK", the following occurs:
- The "name" will be entered for singleTCW ID and "sTCW_<name>" will be entered for the Database.
- The project/<name> directory will be created with files LIB.cfg and sTCW.cfg. These maintain all information you enter.
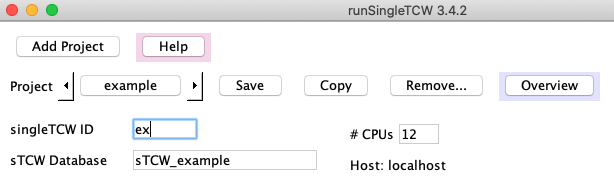
For example, if you enter the name "example", the ID will be "example" and the database will be "sTCW_example".
Shorten the singleTCW ID, for example, to "ex" as shown.
|
|
singleTCW ID: This should be a short descriptive name (2-5 characters, e.g. "ex"). It is used for the
following:
- This can be used as a command line parameter to runDE and viewSingleTCW, e.g. "viewSingleTCW ex".
- If TCW generates the sequence names (if Use Sequence Names from File is not checked),
the singleTCW ID followed by sequential
numbers will be used, e.g. ex_00001, ex_00002, etc.
Instead of using the Add Projects, you may create a directory under /projects and put your sequence files along
with any other optional files (i.e. quality and count); when you select the project pulldown, you
will see your project (the project pulldown lists all directories under /projects).
Input files
There are three possible scenarios:
1. Sequence and count files
The typical input is a file of transcripts and associated read counts. The transcript file is a FASTA file,
where the sequence name must be under 30 characters, using only letters, numbers, and underscores.
The sequence names in the count file must match the sequence names in the sequence file. The count file
is a tab or space delimited file. The first line of
the count file is the heading "SeqName" followed by the replicate names. The replicate names should end in
the replicate number, e.g.
SeqName Leaf1 Leaf2 Leaf3 Root1 Root2 Root3
This defines two conditions with three replicates each. The remaining rows must have the exact same number of
columns. More information is provided in Defining count data.
The conditions will be displayed in viewSingleTCW in the same order as the input.
2. Sequence and quality files
TCW supports assembly of Sanger ESTs, 454 reads, or a mix of these datasets with transcripts. See
Assembly names for more information on this data.
3. Multiple sequence files
You may enter multiple sequence and condition files, which may or may not be assembled. You must make sure
that all "Condition" and "SeqID" are unique, i.e. a SeqID and Condition cannot have the same name.
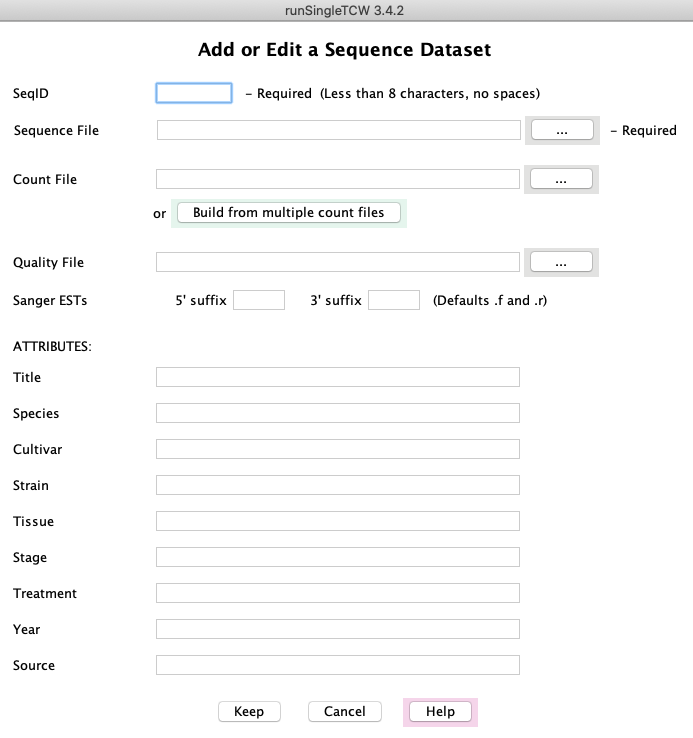
Entering a sequence dataset
|
A TCW project must have at least one sequence dataset, which is a FASTA file of sequences.
Select Add beside the Sequence Datasets and the panel will be replaced with the one
shown on the lower right.
|

|
|
SeqID: Enter the dataset name (a brief identifier) in the first box; it should be a short (3-5 characters) name.
Sequence File: Click the browse button labeled "..." to select the FASTA file of sequences.
Additional information:
- Count File: For already assembled transcripts (e.g. Illumina) or protein sequences, there may be associated count files.
Adding them is covered below in Defining count data.
- Quality File: For Sanger ESTs or 454 data, there may be a quality file (standard Phred quality scores in FASTA format).
- Sanger ESTs: TCW assumes the 5' ESTs have the ".f" suffix and the 3' ESTs have the ".r" suffix. If there
are different from this, enter the correct ones.
- ATTRIBUTES: Enter any additional information
as desired in this section. This information is very important as it provides a description of the data
that is stored in the database and shown on the Overview panel of viewSingleTCW.
After entering the files and attributes, select Keep.
The main panel will reappear with the SeqID and Title added to
the Sequence Datasets table. Additionally, the information will be written in
projects/<name>/LIB.cfg.
Define all datasets, then select Build Database to load the data into the database.
Datasets cannot be added to an existing database.
|
|
Updating attributes
The attribute information can be added or changed after the database is created by
using the Edit button on the main panel;
note, the projects/<name>/LIB.cfg file has to be accessible to change attributes.
|
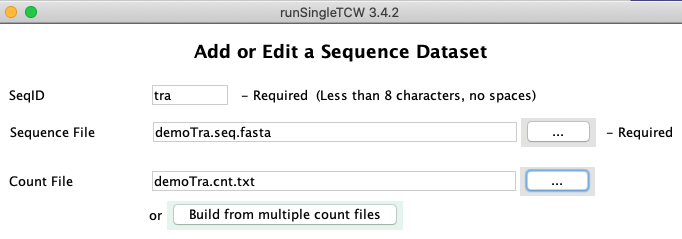
Count File: Click the browse button labeled "..." to select the file containing the table of counts
for the sequences. Alternatively, you can build the combined count file from multiple files, as described in
Build from multiple count files.
When Keep is selected at the bottom of this window, the dataset panel disappears and the main panel returns.
|
|
|
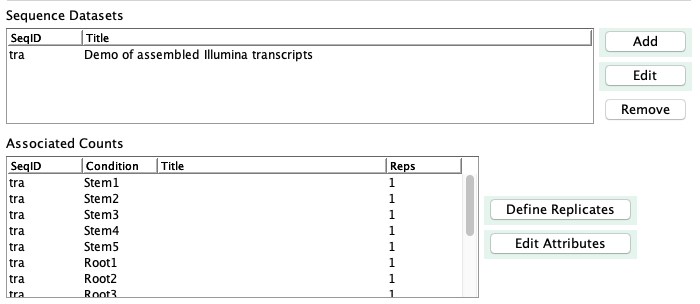
The panel shown on the right is part of the main panel. The
sequence dataset will be shown in the first table, while the conditions (column headings from the count file)
will be listed in the second table.
Use Define Replicates to group replicates, as discussed in the next section.
After defining the replicates, use Edit Attributes to add information for the
conditions, which will be shown on the viewSingleTCW overview.
|
|
|
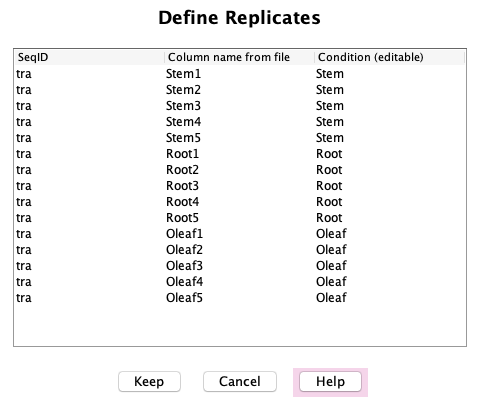
If you have biological replicates, you now need to click Define Replicates to define them.
This brings up the panel shown on the right (example data from "demoTra").
The first column shows the sequence SeqID, which you entered when creating the sequence dataset.
The second column shows the "Column name from file", which are the column headers
in the count file (see example below). The third column
shows the "Condition", which groups the replicates into a single condition.
If the replicates names in the count file are named with the format
"condition name + replicate number" (e.g. Root1),
then TCW can automatically group them correctly.
Otherwise, you will need to edit the
"Condition" column to map your replicate names to their condition. To edit a "Condition", highlight the
row, then click on the appropriate cell (it is a little finicky, you may need to click at the beginning or end or double click...);
it will turn white indicating you can edit the cell.
|
|
|
On Keep, the Associated Counts table on the main panel will be updated, showing
the correct condition list and number of replicates for each (as shown on the right).
In order to add metadata (e.g. title), select a row followed by Edit.
|

|
Naming rules:
- There must not be any duplicate names between the SeqID column of the first table and the Condition of
the second table, e.g. there may not be a SeqID of "Root" in this example.
- There can be NO duplicate replicate or condition names between Sequence Datasets.
The Count File is a
tab or space delimited file where the first line contains
the word "SeqName" (or any label) followed by the condition column headings. If your
file is comma-delimited, they can be replaced with sed -i"" 's/,/" "/g' filename
Example Count File: The following is the demoTra count file, showing the first 4 transcripts and
counts for three conditions, where there is 3 conditions(tissues) with 5 replicates each.
TCW determines the condition names and replicate numbers are from the column headers.
The sequence names must correspond to those in the sequence file.
SeqName Stem1 Stem2 Stem3 Stem4 Stem5 Root1 Root2 Root3 Root4 Root5 Oleaf1 Oleaf2 Oleaf3 Oleaf4 Oleaf5
tZoR_002048 556 572 766 770 777 294 361 291 300 399 264 173 162 407 382
tZoR_147465 1172 1965 1009 1110 2245 10 425 593 251 347 1542 880 1648 3043 1024
tZoR_108557 51 52 73 41 49 2 131 64 70 108 0 10 5 5 10
tZoR_118798 52 51 35 37 33 1 69 138 61 134 8 9 7 21 6
The count values can have decimal points, but the numbers will be rounded.
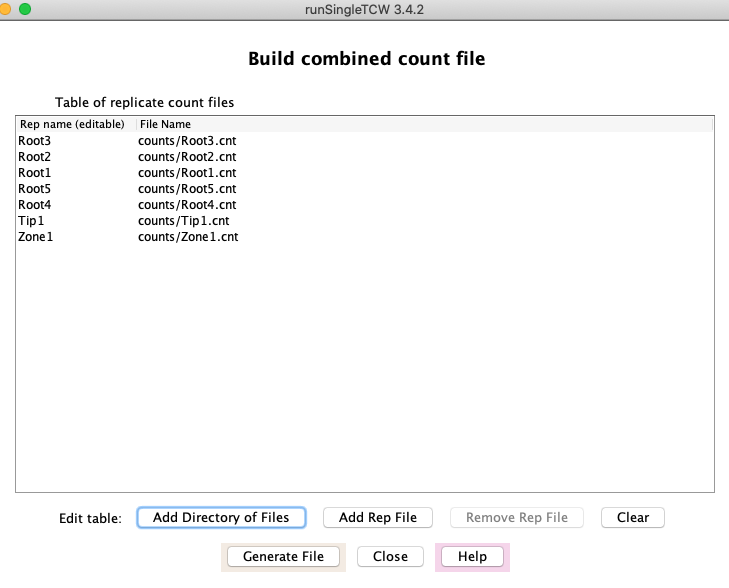
Build from multiple count files
It is common to have separate count files for each sample, in which case,
you can use the Build from multiple count files to generate the combined
count file. This explanation will continue using the "demoTra" example.
The easiest way to handle many sample files is to put them in one directory. Name each
file with the "condition name + replicate number"; TCW parses up to the first "." to determine the condition
and replicate number (the suffix can be whatever you want).
For example, in the directory projects/demoTra/counts are the files:
Root1.cnt Root2.cnt Root3.cnt Root4.cnt
Root5.cnt Tip1.cnt Zone1.cnt
This is a different set of conditions then shown in the "Example count file", where there are 5 replicates for root but no
replicates for tip or zone.
|
As shown in the right, the file prefix (e.g. Root1) is shown in the "Rep name" column in the table on the right,
and is used as the column heading in the combined file. Furthermore, the
replicates for a condition will be grouped together by the text up to the number
(as shown previously in Define biological replicates).
To build the file:
- Select Build from multiple count file.
- Select Add Directory of Files, which brings up a file chooser window; select the directory containing
the files (e.g. "count") and it loads all files from the selected directory, as shown on the right.
- Select Generate File to build the file called Combined_read_counts.csv. Control will return to
the Sequence Dataset panel, and this filename will be automatically entered into the "Count File:" entry box.
|
|
If your files are not in one directory, or not named correctly, you will need to add them individually
using the Add Rep File. You probably will need to edit the "Rep name" column; to edit the name,
highlight the row then click the mouse at the right edge of the entry box (if that doesn't work, trying clicking
at the beginning).
As already described, the replicates are grouped by clicking the Define Replicates button on
the main window.
Instantiation (with optional assembly)
| Go to top |
Skip Assembly:
If the input is already assembled transcript sequences, or protein sequences, or gene sequences,
check this option.
If the datasets are ESTs, or multiple transcript datasets that you want to assemble together,
do not select this option and see Assembly Guide.
Press Instantiate to either assemble or finalize the sequences in the database.
Use Sequence Names from File: If the sequences are NOT going to be assembled, then this checkbox is relevant, as follows:
If you want TCW to name the sequences, do not check this option;
TCW will rename the sequences using the SingleTCW ID followed by sequential numbers.
If you want to use the original names from file, check this option; note the following restrictions:
- Characters other than letters, numbers, or underscores
will be replaced by underscores.
- The names must be under 25 characters. Note that the names supplied by
sequencers are often longer than allowed, which will make this fail.
For instantiation without assembly, this step does the following: (1) the transcripts are loaded, (2) the replicates
are loaded, and the sum of the replicates for each condition are used to compute the TPM (transcripts per million).
Three types of computation are performed:
- Functional annotation: Compares one or more protein and/or nucleotide databases ("annoDBs") to each sequence in the database. If the annoDBs are
from UniProt, add the associated GO annotations.
- Basic annotation: GC content and ORFs, where the ORF computation uses the functional annotation.
- Similar pairs: Compute pairs of similar sequences within the input set.
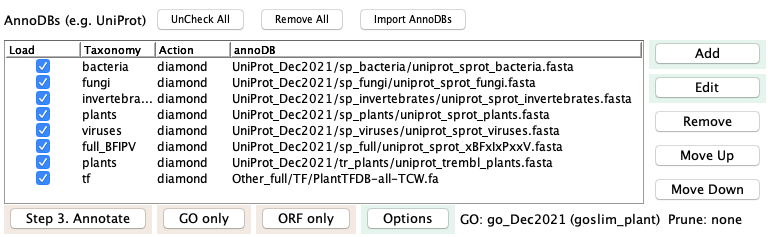
AnnoDBs and UniProt
The term "AnnoDB" refers to a FASTA file of nucleotide or protein sequences,
where the TCW sequences (transcript or protein) will be searched against the annoDBs for functional annotation.
Read Annotation Setup for obtaining UniProt and other annotation databases.
|
Import AnnoDBs provides a way to enter all UniProt databases at once.
If you have used runAS
for the annotation setup,
make sure the last step was to select the AnnoDBs.cfg button, which creates a file of UniProt databases.
Select Import AnnoDBs, which pops up a
file chooser, then select the projects/AnnoDBs_UniProt_<date> (or sTCW.cfg of another project);
all your UniProts will be added at once.
|
|
|
Any additional databases (e.g. Genbank nr) need to
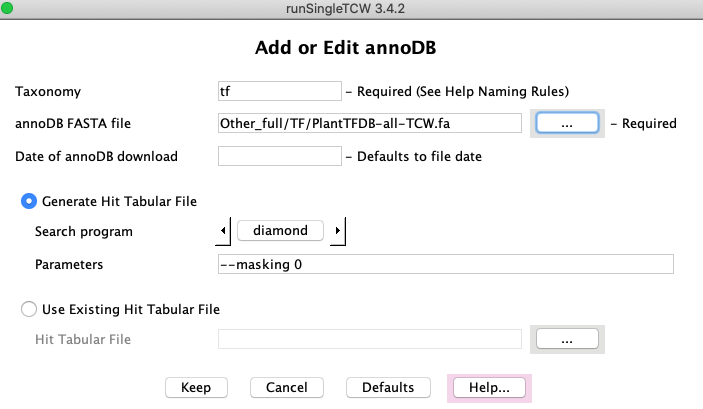
be added one by one. To add an annotation database,
press the Add button next to the AnnoDB table. This brings
up the panel shown on the right.
Taxonomy: this does not need to be unique, but the DBtype must be.
The DBtype is type+taxonomy, e.g. if the type is "sp" and the taxonomy is "plant",
the DBtype will be "SPpla".
The DBtype is
shown in various tables of viewSingleTCW to indicate the origin of the hit.
Read Creating AnnoDBs from other databases to see how these were formatted.
Also, see the Demo Add non-UniProt annoDBs.
| 
|
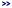 Generate Hit Tabular File:
Generate Hit Tabular File:
Search Program: select DIAMOND or BLAST.
Parameters: defaults will be provided based on the search program selected,
which can be changed.
Use Existing Hit Tabular File:
You can supply your own hit results file (must be in tabular format).
You must still provide the annoDB FASTA file as
it extracts the description and species from it.
The Options button below the AnnoDBs table provides additional options for:
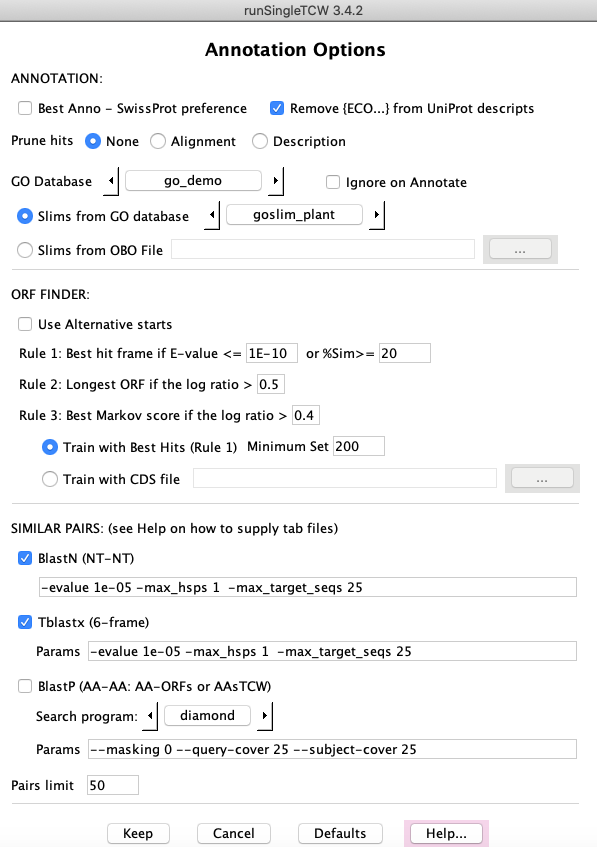
- ANNOTATION
- ORF FINDER
- SIMILAR PAIRS
The second option and part of the third are not available for TCW database created from protein sequences.
ANNOTATIONS
Best Anno -- SwissProt preference: A SwissProt hit will be assigned Best Anno over a non-SwissProt hit
if its bit-score > 0.7 * highest bit-score.
Remove {ECO...} from UniProt descripts: Most UniProt descriptions have {ECO...} text, e.g.
>sp|A0A096SRM5|708A6_MAIZE UDP-glycosyltransferase 708A6 {ECO:0000303|PubMed:24045947}
Selecting this option will remove the {ECO..} portion, e.g. remove {ECO:0000303|PubMed:24045947}.
Prune hits: See the Annotation Guide Prune Hits section
for a details discussion. The options are:
| None | Keep all hits found using the search parameters provided on the Add or Edit AnnoDB panel.
| | Alignment | If all alignment columns (e.g. bit-score, E-value, %similarity, etc)
are the same between two hits for a sequence, only keep the best.
| | Description | For each annoDB, if two descriptions are exactly the same (case-insensitive)
the best hit will be retained.
|
The Alignment and Description optionally use the number of GOs per hit to aid in determining the
best hit to keep. Hence, you will want to enter the GO database name before running Annotate.
GO Database (GO, KEGG, EC, InterPro, Pfam annotations)
See Annotation Setup for creating the GO database.
Once the GO database is created, it can be selected, as shown on the right. Once selected, it will display
the available GO Slim categories in the drop-down below it; alternatively, a OBO formatted file may be entered.
Ignore on Annotate:
If you do not want Annotate to perform the GO annotation, select Ignore on Annotate.
The GO annotation can be added with the GO Only button.
ORF FINDER
GC content and ORF finding is always performed when Annotate is performed.
The ORF finder uses the annoDB hits to aid in determining the best open reading frame.
See the ORF document on the ORF finding options and
details on how it works.
NOTE: The only default changed for the Minimum Set (default 500);
since the dataset does not have that many sequences, it is changed for the demo.
| 
|
SIMILAR PAIRS
The annotator can compare all sequences and determine the top N pairs,
where their alignments can be viewed in viewSingleTCW. Only the blastp
option works for AA-STCWdbs.
More information on all the above is provided on the Annotation Options panel Help page
and Annotate Details.
Adding to annotation
Additional annotation can be added at a later time;
see Update and Redo annotation
in the Annotate Details Guide.
|
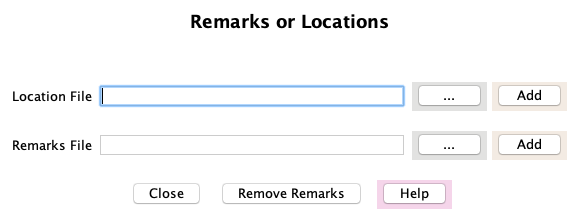
Select the Add Remarks or Locations button at the
bottom of the runSingleTCW panel; the panel on the right will replace the main panel.
Details of each function is provided below.
Both the locations and remarks can be search and viewed in viewSingleTCW. Remarks
are a very good way to add additional information to the sequences.
|
|
Add Location File
Select the "..." on the Location File row, select a location file, and press Add on the same row.
The file is a set of rows where the first word of each row is the sequence ID and the rest of the row is the format:
group:start-end(strand), e.g. SC_1:392-496(-)
The "group" would be the supercontig, scaffold, chromosome, linkage, etc.
If TCW can extract numbers/X/Y from the end of the group (e.g. chr1, chrX),
it adds a column containing just the "Group" number that can be sorted numerically in viewSingleTCW.
The sequence ID must match a sequence ID in the database,
so you probably will want to "Instantiate" the sequences using "Use Sequence Names from File".
A script is available, scripts/extractCodingLoc.pl, to generate the transcript sequence file from a
genome sequence and GFF3 file. It also generates the location file in the format needed by TCW. It only works with
a subset of the GFF3 files, so probably needs to be modified for your GFF3 or GTF file. It uses BioPerl.
The group name, start, end and strand are columns in the TCW database that can be viewed in viewSingleTCW
by selecting the "Columns" tab on the left, then checking the columns under "General".
Add Remark File
Select the "..." on the Remark File row, select the file of remarks, and press Add on the same row.
The file is a set of rows where the first word of each row is the sequence ID and the rest of the row is the Remark.
- Single and double quotes will be changed to spaces.
- Semi-colon will be changed to a colon.
In viewSingleTCW, the User Remark can be viewed by selecting the Columns tab,
then checking the User Remark column under General.
The remark can also be search on in the Basic Queries Sequence; this is a great way to add
additional information about your sequences.
If you make the remarks "keyword=value", you can then search on the keyword
to get a specific group of sequences.
Remove Remarks
Selecting this button will remove all user remarks. There are also "TCW Remarks" that are added during ORF finding; these
are not removed.
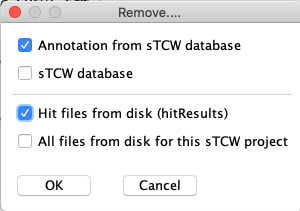
Remove...
| The image on the right shows what can be removed. The checked
items are useful for redoing parts of the annotation, as discussed in Annotate Guide
Update and Redo annotation section.
| 
|
Trouble shooting
If errors occur, a message is written to the terminal
and the Java stack-trace is written to the file sTCW.error.log. This can
be sent to us so we can help you trouble shoot the problem, that is, if the
message to the terminal is not sufficient to indicate how to fix the problem. NOTE:
errors are appended to this file, so if an error keeps re-occurring without getting
fixed, the file can get quite large.
If the information on the runSingleTCW panel does not look right, remove
/projects/<project>/LIB.cfg to start over. You can try fixing the problem
by editing this file, but it is important to format it correctly.
If that does not work, email tcw@agcol.arizona.edu and we will guide you on how to enter the information.
If you have many sequences (e.g. transcripts) in the database and/or many annoDBs,
this can take a lot of memory. Running Annotate sets the memory to 4096, which may not be
enough; in this case, once runSingleTCW is ready to annotate your database, exit and run from the command line:
./execAnno <project>
You can increase the memory size in the execAnno script.
Also see Trouble shooting.
TCW integrates several different R packages for computing differential expression of transcripts, including
EdgeR and DESeq2; an R script containing the R commands to compute DE can also be supplied. GOseq is supported for
computing DE enrichment of GO categories. The DE computations are pairwise, i.e. conditions are compared two
at a time. Each comparison results in a
column added to the database, which may be viewed and queried. The DE modules are accessed either
through ./runDE on the command line.
For full details on the DE modules, see the Differential Expression Guide.
IMPORTANT DETAILS
Directory structure and configuration files
| Go to top |
Users do not ordinarily need to look at the underlying directories and files used by TCW, however they are described
here since it may be helpful at times.
When a project is added with Add Project, runSingleTCW
creates a directory under /projects with the user supplied name
(referred to here as <project>).
The projects/<project> directory has a
LIB.cfg file where runSingleTCW saves all the library information and
a sTCW.cfg file where runSingleTCW saves all the assembly and annotation information.
Though you can put your data files anywhere that runSingleTCW can access,
you may want to put your data
files in the projects/<project> directory in order to keep everything in one place.
Also, the /DBfasta directory contains a subset of the UniProt files for the demo; this is
a good location to put all annoDB files.
The three major steps write to the projects/<project> directory. The Annotate
step puts all hit results in hitResults subdirectory. Hit files are NOT removed as they may be reused.
As mentioned above, runSingleTCW creates LIB.cfg and sTCW.cfg files under
the /projects/<project> directory. Once created, you can run the three steps from the
command line instead of through the interface.
| Action | Executable | Configuration
|
| Build Database | execLoadLib | LIB.cfg
|
| Instantiate | execAssm | sTCW.cfg
|
| Annotate | execAnno | sTCW.cfg
|
The LIB.cfg and sTCW.cfg files can be edited with a text editor, but be careful as
runSingleTCW and the executables expects the syntax to be exactly as it writes the file.
Each command line script takes as input the <project> name, along with some optional flags; execute
the script followed by -h to see the flags (e.g. ./execAnno -h). All three take as input
the "-n", which suppresses any prompts and uses defaults (as described by -h); this is good for batch processing.
The instantiation (or assembly) computed TPM (transcripts per kilobase per million); in order to compute the
RPKM instead, execute:
./execAssm <project> -r
Once a project is created, it is viewed and queried using viewSingleTCW.
This program is launched either:
- From the command line (./viewSingleTCW), which
brings up a panel of mySQL databases with the sTCW_ prefix, where databases can be selected to view.
- From the command line using the singleTCW ID or sTCW Database
as a parameter (e.g. viewSingleTCW tra).
- Through the button at the bottom of the Manager interface (Fig. 1).
The TCW Tour shows the various displays.